
终结篇:不务正业了近一个月,终于有点成果了,但是并行计算也就到此为止了,不能再做了,毕业的压力山大。按我本心来说,单纯做水文模拟实在是没劲,因为这就像,大道理谁都懂,可是真正做起来完全不是那么回事儿,那些“道理”在极其复杂的实际情况下未必就是对的,做这些非常不“靠谱”的试验就像是在玩扫雷,即便我最后通关了,要么是我知道这个地方有雷,而有意地避开了,要么就是我“运气好”,没有踩到雷而已。
扯回正题,先亮一下最后的结果:
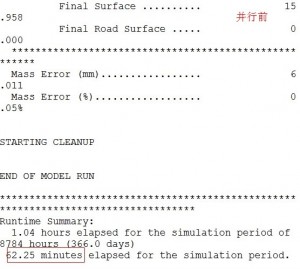
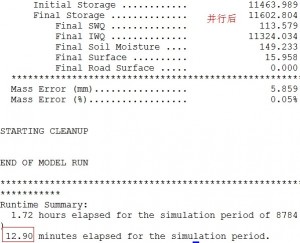
如图,在所里的工作站上,使用原始的DHSVM模型(或者说串行版本的模型)进行为期一年的水文模拟,需要时间约为1小时。而使用我并行化修改后的模型进行一年的水文模拟,在8核情况下,用时12.9分钟。
也就是说,8核情况下,并行修改后的模型的实际执行速度是串行版本的5倍左右。
为什么不是完美的8倍呢,个人认为有两方面原因:其一,我并没有把所有串行程序都并行化,仍然有部分程序是串行执行的(如果你想知道为什么,可以继续往下看);其二,本人水平有限。
if,你有兴趣了解如何实际进行OpenMP并行化,
then, 后文应该会对你有所帮助的。
else if,你只是想测试使用这个模型的并行化版本,
then,可以直接向我索要。
else, 耽误您的时间了,我很抱歉。
在上一篇日志中,主要是解决了冰川模块的并行化修改以及实现了自动进行子任务划分,后来我就进行了近一个月的模型调试和并行化工作(其实我的主要任务是把模型的模拟值调试到与观测值接近的水平,并行运算只是我给自己安排的娱乐项目,所以并行化的工作只能在其中穿插进行)。
首先说一下,上一篇日志里的东西,实际上,自动进行子任务划分使用水平划分就足够了,而且也是最合适的(相比垂直而言),后面做的垂直划分和“书架式”划分虽然可以提高负载均衡,但是在实际执行效率上未必会有好的效果(我绝对不会承认我当时做那么多工作实际上是因为自己太菜了, )。
)。
本日志就要解决剩余的部分了。而实际上,这部分内容才是重中之重,上一篇日志只是做了些基础工作,真正要提高程序的执行效率,还得用实践来检验。实际上在上一篇日志说到的那三个要重点修改的函数并不足够,而且修改的Main_gl函数只是每月执行一次,其实没有进行并行化修改的必要。
DHSVM模型中需要并行化的函数/过程为以下4个:
RouteSubSurface、Cell Loop、Aggregate、RouteSurface
本着先易后难的原则,下面先修改“RouteSubSurface”函数。
目测一下,这个函数中有3个外层for循环,第一个做初始化,第二个是主要的计算,第三个是善后(释放内存)。所以,修改第二个循环是主要任务。这个函数的修改难度略高于冰川模块,因为,该函数还会调用一些子函数,如果只是在本函数内做并行化修改,就很可能引发错误,因为我们无法确保被调用的函数是线程无关的。所以,主要难度在于麻烦。
首先,从顶层修改,由上一篇日志已经发现:子任务分解时,负载权重的设置非常重要,因为它直接关乎能否真正达到最优(可能说较优更合适一些)的负载平衡。由于只是4核,所以我这次只使用水平划分。
第一个循环只是简单的初始化,用时较少(12ms),所以我只是简单的加上了OpenMP编译指令:
#pragma omp parallel for num_threads(ncores)
第二个循环则是主要修改目标。
先测一下串行用时,如下
1st loop in RSS is: 12 ms
第二个循环的形式如下:
for (y = 0; y < Map->NY; y++) {
。。。。。
}
}
}
乍一看,只需要像冰川模块一样只计算Mask栅格的权重即可,但是在循环体内部,还调用了“channel_grid_inc_inflow”这个函数,该函数的实现如下:
}
很遗憾,红色部分表明该函数是无法并行的,因为这是一个单向链表,我如果强行把它提取出来,费时费力不说,最后还可能因为内存溢出而失败。所以这里只能采用折中的方法,可以发现, 每次只有“later_inflow”这个变量会使用传递进来的mass值,所以我的做法是在顶层创建一个mass的记录器(记录每个栅格的mass值的数组),然后待循环结束后,再统一加入需要更新的河道节点上。这样就可以去除栅格间的依赖性,从而避免写竞争的出现。
然而,事情还没有结束,在循环后部又发现:
for (k = 0; k < NDIRS; k++) {
这里,本栅格的水流会影响到周围栅格的水流值,但是,相比单向链表来说要容易解决很多,只需要用到我上一篇日志中实现的划分方法,把“interval”(隔离带)设为2,就足以保证各个线程不会出现写入同位置栅格的问题。具体实现如下:
/* 并行运行各个子任务 */
。。。。。。
/* 串行或并行运行隔离带内的栅格 */
。。。。。。
/* 串行运行channel_grid_inc_inflow函数 */
。。。。。。
看下运行效果:
2nd loop in RSS is: 46 ms
46对比132,速度只提高为原来的3倍左右,主要原因可能有两方面:(1)串行比重的影响 (2)并行线程之间并非完全独立
但是这还不是主要的问题,因为“RouteSubSurface”这个函数总用时400ms,而这三个循环加起来=48+23+20=91ms,另外300ms哪去了?结果,发现是第一和第二个循环之间有一个子函数“HeadSlopeAspect”的影响,该函数运行时达到270ms,所以有必要对该子函数进行并行修改。
有了前面的基础,改这个函数就容易很多了,同样是把隔离带设置为2,采用水平划分,重新编译运行,得到:
time of loop in HeadSlopeAspect is: 76 ms
76对比270,差不多3倍半的速度,效果还可以。
可是如果整体看下这个函数的运行时间的话,还是觉得加速比太低了,果然,发现一个有趣的地方:


上面是所需内存的初始化部分,只需要3个大内存块用于存放实际数据,4个小内存块用于存放指针即可。
释放的时候,直接:
这样,这部分的执行时间就趋近于0了。
综合看来,RouteSubSurface的并行化效果还是令人满意的。
然后,就是修改“Cell Loop”部分了,这一部分比较复杂,其源码如下:
看着就头疼, 虽然只有两个主要的函数:MakeLocalMetData 和 MassEnergyBalance,但是只看名字就知道,内容会有多么丰富,而且传入参数极多,这就需要细心甄别了。
经过仔细核查,MakeLocalMetData函数没有写共享变量的情况发生(长吁),但是MassEnergyBalance就没这么好过了,因为,直接对Cell Loop执行并行的结果是报出段错误,这说明在这一代码块里必然存在写竞争的问题(可能不够严谨,但大抵如此)。
所以,我实施的策略是,对于MakeLocalMetData直接进行并行化,而MassEnergyBalance这个函数就需要进行改造了,经过仔细比对,这个函数的线程共享内存是辐射数据,而且函数内还调用了一个对于全局数组都会产生影响的一个子函数,所以,我把辐射数据在执行前进行分解、缓存,然后在函数执行完以后在加起来,而对于那个子函数则是把其需要的数据也缓存出来,然后在最后串行执行即可。如下

channel_grid_inc_inflow函数会把当前的水流累加到流向的栅格中去,而totalrad是全局的辐射记录器,各个线程都会用到。所以,这部分代码在我修改的版本里必须是串行执行的。实际应用中发现,这部分代码也才耗时1秒左右,所以这里保留串行的代价并不大。
最后,锦上添花的修改了Aggregate函数和RouteSurface函数,因为这两个函数的耗时并不严重,但是考虑到也会影响加速效果,所以也一并修改了。在修改的时候也发现了两个有趣的问题:
其一,Aggregate函数的串行结果和并行结果不一样。这是因为这个函数是做统计的,而统计的变量类型是float,float型变量的有效数字只有6、7位,所以,我改变了数值累加的“流程”(为了并行化),会对其结果造成一定影响,这个很容易验证,把OpenMP编译指令去掉,监视一个变量的值,在执行这个程序就会发现,该变量值和串行结果完全一致。
其二,cache miss不是传说,是真实存在的。如下,

这是我为了统计各个线程的数据而创建的结构体,也许你会感到奇怪,为什么要用结构体,那个buf是做什么的?一切都是为了减少cache miss,如果两个线程访问的不同数据在内存中位于同一个cache line中,那么一样也会发生伪共享问题,所以,我需要确保这些数据”隔开一定距离“,那个buf就是缓冲带的作用,而结构体可以把要引用的内存打包聚集起来,以确保有buf做间隔,而且还会提高cache的空间重用性。
以上,基本上是我慢慢“回忆”写完的,写了一会儿就发现实在是有点累了,很多细节都不愿意再提了,上面这些只能说是其中的一小部分,真正对这方面感兴趣的同学可以跟我私聊。而且,由于水平有限,很多修改想来也是存在问题的,也请路过的大神不吝赐教。
最后的并行效果就是文章开头里写的那样,有比较明显的并行加速效果,但是从结果来看还是有明显的提速空间的,只能留待以后解决了。