
这篇日志以及这个工具可能会使需要做以下两种工作的同学受益:
(1)需要对大量的高分辨率栅格数据进行投影转换和重采样
(2)使用MOIDS各种产品进行区域、及全球尺度的研究,也就是需要对多个条带的MODIS产品进行拼接、重投影和重采样工作
本程序对于第二种情况有奇效,如果学会使用本程序,将会极大得减少数据预处理时间,使时间成本大大降低。
咳咳,老夫再唠叨一次,如果你是要使用任何MODIS产品进行多年的区域尺度研究,那么这个工具对于你的数据预处理工作将会大有益处,除非你根本就不在意花多少时间。。。
正文:
这个小程序主要适用于以下情境:做大尺度研究,经常需要对大范围、高分辨率栅格数据进行重投影及重采样。通常,在这种情况下,时间成本很高,仅处理单个文件就可能需要较长时间。而我写的这个小程序可以有效解决这一问题,不过,需要指出的是,这个程序只适用于使用“最近邻法”进行重采样的情况,也就是说重采样之后不会改变原始数据的像元值。
程序原理: 在很多情况下,我们使用诸如MODIS,AMSR-E这类遥感产品时,一般都会使用“最近邻法”(Nearest)来进行重投影及重采样。让我们细想一下,其实,这一步的主要时间都用在了计算输出数据的像元位置,而由于使用的插值方法是最邻近法,实际上我们并没有真的插值,我们只是将原始数据按一定投影规则分配到了输出文件的对应栅格里,而理论+实际上,这种“投影规则”对于不同时间的同“批次”数据来说都是一样的,那么,挖掘机就来了,我们为什么每次都要重新计算一次呢?这岂不是在浪费时间!!!所以,这个程序是直接利用 用户提供的“投影规则” 来进行重投影及重采样。说白了,我实际上没有进行任何投影计算,我只是在“搬运”数据,i.e. 我不是在创造真理,我只是真理的搬运工-_-!。所以,我更愿意把这个程序定义为一个“外挂”,而且是加速挂。
实话说,这个程序的原理极其简单,即便是使用IDL、python、R、matlab等脚本语言,也都可以很快实现。我最初就是在课题组里的工作站上使用R语言进行了覆盖整个青藏高原的地温数据的“搬运式”重采样和重投影,效果极佳,因为完全不需要进行常规的重投影和重采样工作,这使得我原本需要一个月才能完成的重投影工作只用了不到1天就全部做完。
但是我后面还要做很多不同数据源的重投影工作,使用R或者其他脚本来做总感觉有点不尽兴,所以我就写了这样一个小工具,考虑到代码执行效率的问题,程序完全使用C编写(编译环境是VS2015RC)。
下面介绍一下这个程序:(我觉得这对我烂到渣的语言表达能力是个巨大挑战)
主界面
程序名为 carry,取”搬运“之意
如前所述,此程序实际上做的工作仅仅是“按图索骥”,但是,我们如何找到这个“图”呢。下面我用两个实际案例来介绍这个工具的基本功能
.1,案例一:常规TIF数据投影转换
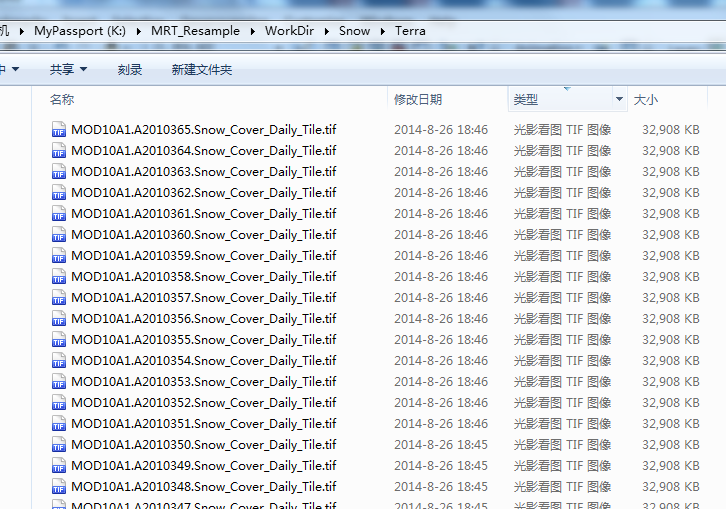
比如,我需要对这个文件夹下面的3000多个积雪覆盖数据文件进行批量重投影,重采样工作,注意它们是TIF格式的,本程序为了简化实现,常规GIS格式中只支持TIF,我相信这是最常见,最通用的空间数据格式。这些文件的空间信息如下,


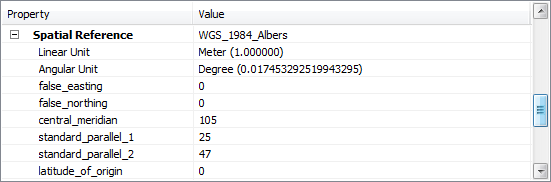
单个文件的总栅格数为33623364,即3000多万个栅格,采用的是albers投影,假如我们需要将其转换为wgs84地理坐标系(当然这样做其实比较傻,但是这里只是一个演示)。如何使用本程序来实现呢?
很简单,如果我们知道原始数据中各行各列最后都“搬”到了输出文件中的哪个位置,我们实际上就掌握了重投影和重采样的最终结果。也就是说我们只需要提供重投影之后的行号和列号文件,就足够了。
那么,我们首先使用carry生成行、列号文件
cmd界面下,切换到carry所在目录,输入如下命令
![]()
解释一下:-f 选项用于指定参考文件,或者叫模板文件,也就是任一输入文件; -c 文件指定了输出的列号文件的路径,-r 指定了输出的行号文件的路径; -T选项设定之后,即表示程序需要生成的是tif格式的文件,与之相对的是-V选项,它表示命令程序生成CSV格式的文件,这个选项在后文的MODIS特例中再表。
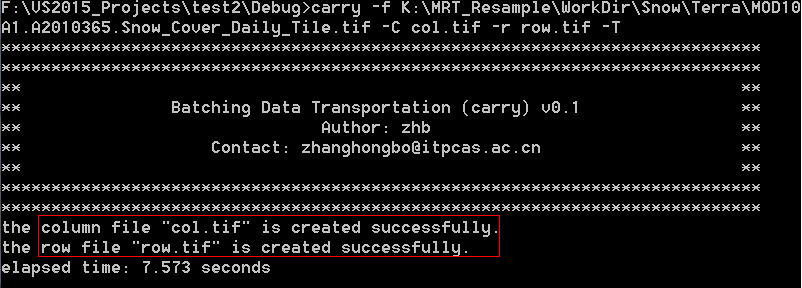
如上,carry成功的生成了行列号文件(虽然这太小儿科了,但还是得验证一下-_-!)
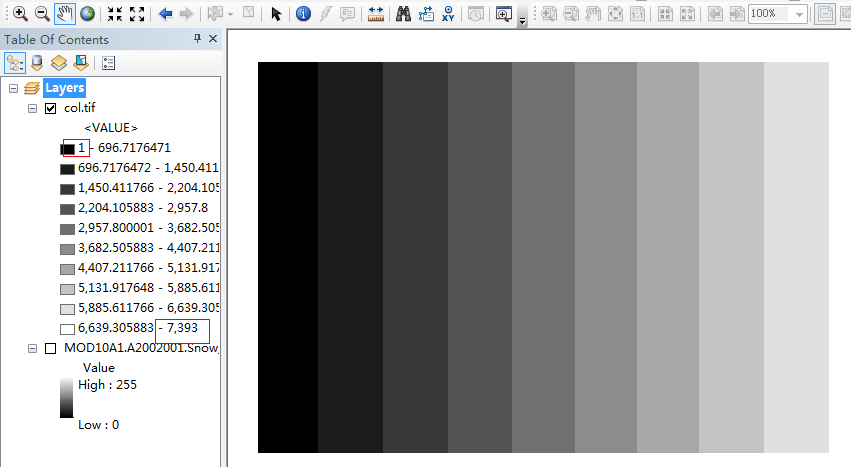

显然,行列号文件都是正确的。然后,我们像对待普通输入文件一样,对行列号文件进行由albers到wgs84的投影转换。
分别命名为row2.tif和col2.tif。
好了,我们现在有了投影变换后的行列号文件,我们就掌握了投影规则,现在就可以进行实际的“数据搬运”了。
![]()
解释一下:-d选项指定了输入数据,-C和-R则指定了刚刚生成的行列号文件,-O指定了输出文件的路径,命名为resample.tif
值得注意的是,-n选项,它表示强制程序在输出文件中设定“nodata value”,也就是无值栅格。这是一个很有意思的选项,我在程序里设置了-n和-x选项用于不同需要的nodata value的设置方案。这个暂且不表。
为了跟常规的投影变换方式进行对比,现使用Arcgis对文件名为MOD10A1.A2002001.Snow_Cover_Daily_Tile.tif的输入数据进行投影变换,如下
生成的文件命名为:projected.tif
将其与使用carry生成的resample.tif进行比较:
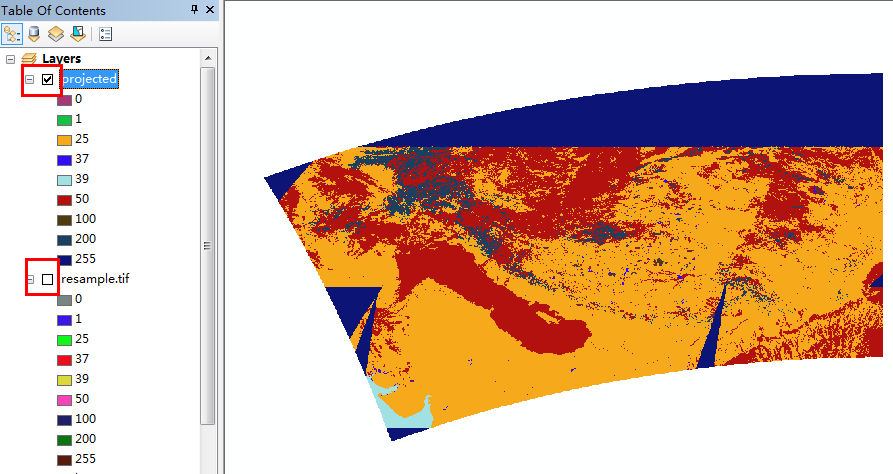

二者完全一致这验证了程序的正确性,然后比较一下消耗时间:
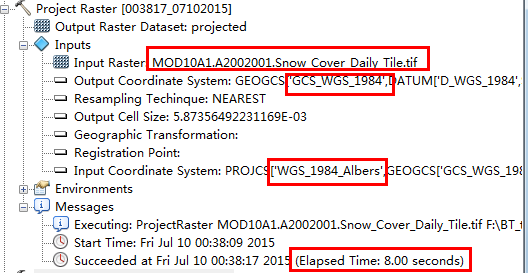
如上,Arcgis用时8秒钟。

而,carry仅用时3.32秒。这个案例其实并不足以表现carry的效能,因为这个投影转换比较简单,对于一些复杂的投影变换算法,比如由正弦投影到albers的变换,使用carry来做所节省的时间显然会更多。
下面介绍真正的重头戏,使用carry对MODIS数据进行重投影和重采样。
二、MODIS积雪产品重投影
这里其实有很多东西可以讲,但是,为了让这篇日志更加简洁,我就只描述处理流程了。
测试数据如下:
为MODIS逐日积雪产品,500米分辨率,这里只选用了第一天的数据,共8个条带,每个条带有2400行,2400列。
(1)生成MODIS数据的行列号文件以及条带号文件 (TXT格式)
![]()
这里比较特殊,当设定了-v选项之后,-c和-r都不再指定文件,而是给出列数和行数,至于为什么要这么做,接着往下看就知道了。-B给出的是需要用到的条带数量。
(2)生成向导文件:“伪造” MODIS数据
这里需要解释一下,什么是向导文件。既然这个程序的工作是数据搬运,那么应该如何搬运呢,实际上就是依照行列号和条带号在投影转换后的文件中的分布来进行,这些文件不仅提供了行列分布,而且给出了最终的投影信息,而这些对于基于最邻近法的重投影和重采样来说就已经足够了!
但是,MODIS产品在重投影时是有一个权威的转换工具MRT的,我们又如何使用MRT得到我们需要的行列号和条带号呢?我曾经想过hack MRT来达到目的,但是这样太出力不讨好了,毕竟年纪大了,精力有限。。。所以,我就退而求其次,对MODIS产品进行“伪造”,让MRT我们的行列号和条带号数据当做普通的MODIS数据来对待。
这就需要用到一个HDF Group的官方软件:HDFView。用HDFView依次打开各条带文件,并输入对应的条带号文件和行列号文件,这里用户需要记住导入的位置并记住条带顺序。这里需要特别指出的,积雪产品的数据位深不足以容纳行列号的数值,那应该怎么办呢?很简单,MODIS有很多其他产品,总会有位深满足要求的,只要维度一样,就可以拿来用。我这里用的是MOD09GA产品来制作伪造的MODIS行列号文件和条带号文件。
下面仅以列号为例,我选择其中一个子数据集输入刚刚生成的列号文件,如下
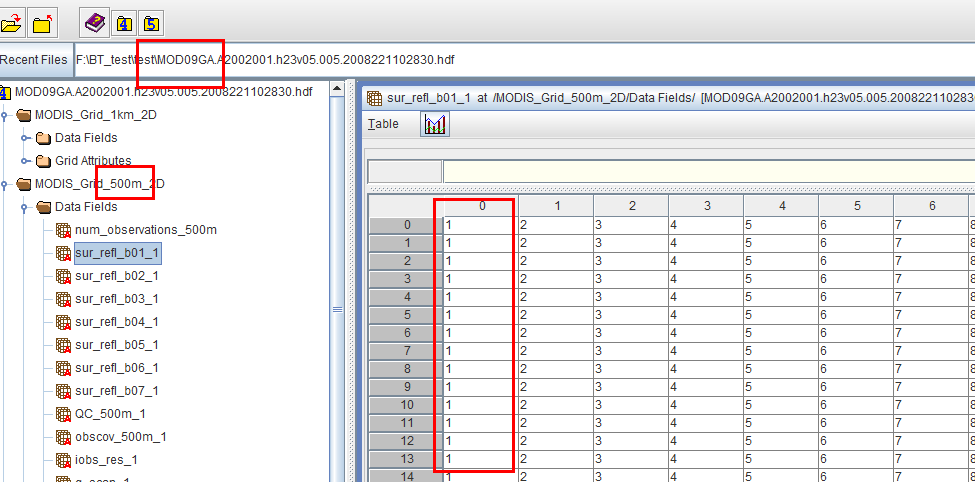
然后往下依次输入行号和条带号,并记录他们所在的波段名称
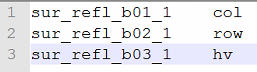
最终生成了投影转换之后的行列号和条带号文件,分别改名为col.tif,row.tif和hv.tif
(3)搬运数据
首先,我们需要准备一个条带输入文件,也就是需要拼接的条带:
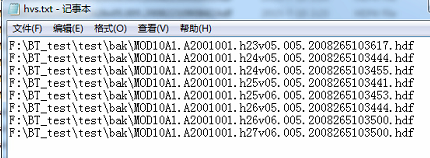
保存为hvs.txt
然后,再确定我们要提取的波段,这个可以在地铁站的PRM文件里找到,比如
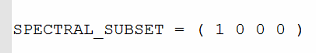
这表示我们只想提取输入数据中的第一个波段,在积雪产品里,第一个波段是“Snow_Cover_Daily_Tile”
在携带中,可以使用-S来指定,比如:-S“1 0 0 0”
好了,现在进行实际的输出操作:
![]()
-d指定输入的条带文件,-B指定条带号文件,-c和-R同前,-o指定了输出文件的路径
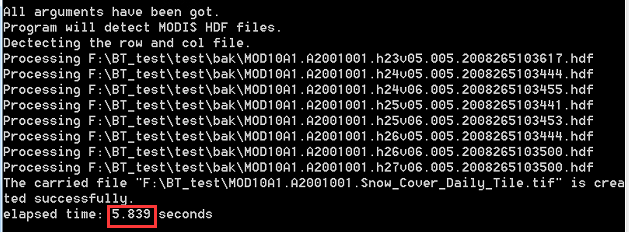
任务完成,仅耗时6秒
然后,跟使用MRT进行重投影的方式进行一下对比,如果使用捷运来做同样的工作的话,会需要多长时间呢?
![]()
![]()
也就是大约12分钟,12分钟对比6秒!这是什么概念呢。假如我们需要对10年的MODIS双卫星积雪产品进行重投影和重采样的话,那么需要的时间= 365 * 10 * 2 * 12/24/60≈60天,而使用携带的时间= 365 * 10 * 2 * 6/3600 = 12小时,也就是半天。
但是,我们还是需要验证一下进行输出的结果和MRT做出的结果是否一致:一个简单的方法就是比较它们的栅格统计量
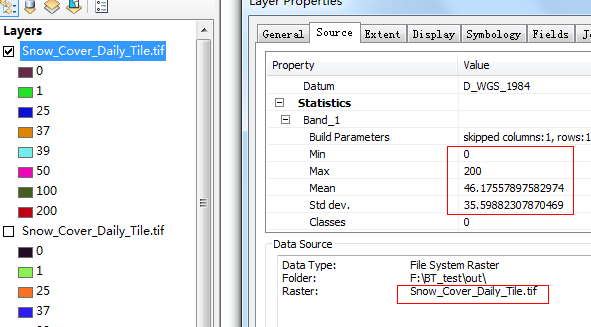
这是使用MRT进行投影转换得到的结果,记住均值和标准差。
而后看一下carry得到的结果:
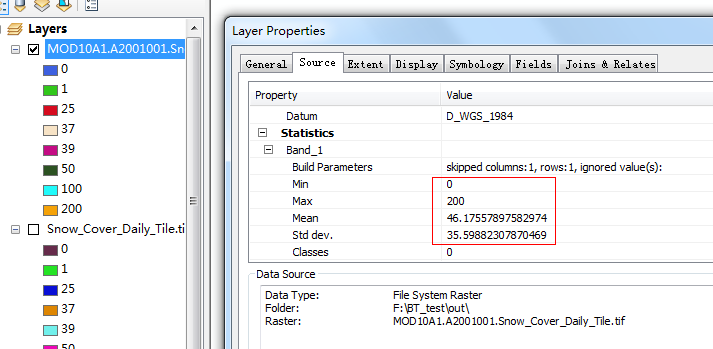
完全一致,这表明carry实现了与MRT相同的效果,但是携带只耗费了MRT 120分之一的时间。
(4)批处理
前面只是做了单个数据的输出,那么如何进行批处理呢?我参考了MRT的工作模式,使用批处理脚本的方式来做,比如window下写bat脚本,Linux下写bash脚本。为了方便用户使用,我随后编写了一个java程序,用于自动生成批处理脚本。
这个自动生成批处理脚本的java程序取名为:carry.jar
cmd下输入如下命令:
![]()
java -jar carry.jar是让java虚拟机载入并运行这个java程序,这就不必多说了,大部分jar包都是这样运行的。至于后面的选项,-d 用于指定输入文件所在的目录,-o 指定输出的目录,其他选项全部是传递给carry的,一定要写对了。回车执行该命令
如果没有报错的话,在输出目录下会有包含了每日条带文件路径的列表文件:
打开其中一个,
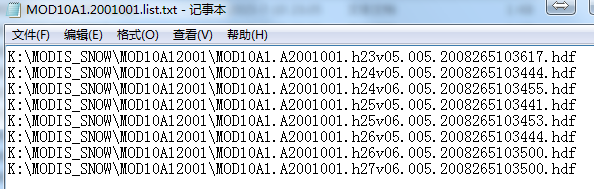
这些文件会被批处理脚本使用
在carry.jar所在的目录下会生成最终的批处理脚本:carry.bat

其内容如下:
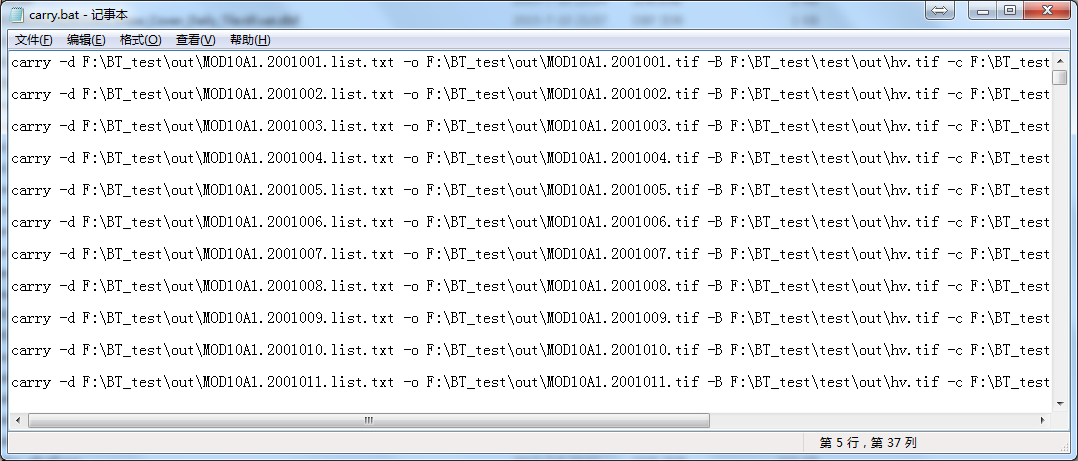
这与MRT中的批处理脚本如出一辙。
用户只需要在carry主程序所在的目录下,调用这个脚本就可以进行批处理了。

如上图,bat文件中的各条命令被逐一执行。。。
三、讨论
(1)关于无值数据
俗称 nodata value,有些数据文件是带有无值栅格的,也就是mask之外的栅格,而有些数据文件是没有的,nodata value到底该不该设置有的时候还是让人挺纠结的,本程序在对待nodata value时采用如下策略:如果原始输入数据中有nodata value,那么输出数据也会有相同的nodata value,如果原始数据没有设置nodata value,那么程序将会根据用户输入的选项来判断:如果设置了-N 选项,就表示程序会强制生成一个nodata value,该值以各数据类型的默认nodata value为准,比如有符号16位整型值的默认nodata value为-32768。但是,有的时候,默认的nodata value却是数据中的一部分,不应该被剔除,这个时候,该怎么办呢?也没问题,本程序提供了-P选项,表示程序会对输出文件进行数据类型“提升”(Promotion),以更大的位宽来存储数据,但是这同时会带来一个问题,就是输出文件的体积,如果不压缩的吧,理论上会增加一倍。
(2)该程序的“扩展”功能
这个程序还有一个隐含技能:如果你在重投影之后还需要进行不改变像元值的重采样和掩膜裁剪操作,那么此程序还可以将这部分操作一起替你省了!因为,你只需要提供重采样和mask之后的行列号文件(如果是MODIS产品,还需要条带号文件)就可以达到目的。
(3)关于程序中的索引选项
我觉得这个选项,最好不要使用,当初在编写时,只是为了表明,使用行列号和使用索引号本质上是一样的,但是,索引号的值使用短整型显然是不够的,而整型数据对于MODIS产品来说,可能很难找到合适的波段。所以,我推荐使用-r和-c选项,而不要使用-i选项
四、程序下载
Note:该程序完全免费,如您使用该程序进行批处理,请在文章中指明程序名称(carry)和本网址(http://hongbozhang.net/wph/?p=43)。
下载网址:
https://pan.baidu.com/s/1Gh-XdBXlcEkDuK_HRd1CGg
提取码:6gsk