
 。 在写这个程序之前还是有点“野心勃勃”的,but,因为害怕影响毕业,所以我并没有选择使用TerraLib这种开源GIS库(那海量的BUG最终把我吓退了)来进行我的工作,而使用Engine则大大降低了实现难度,导致我现在做任何事情都兴味索然。我的博士选题中的一项重要内容是发展一个基于遥感数据的、实用的新参数化方案,目标是估算出在很多水文模型中会被用到的三个物理参数,即:降雪临界温度、融雪基础温度和温度递减率。本文实际上描述的是第一个参数化方案的实施过程。
。 在写这个程序之前还是有点“野心勃勃”的,but,因为害怕影响毕业,所以我并没有选择使用TerraLib这种开源GIS库(那海量的BUG最终把我吓退了)来进行我的工作,而使用Engine则大大降低了实现难度,导致我现在做任何事情都兴味索然。我的博士选题中的一项重要内容是发展一个基于遥感数据的、实用的新参数化方案,目标是估算出在很多水文模型中会被用到的三个物理参数,即:降雪临界温度、融雪基础温度和温度递减率。本文实际上描述的是第一个参数化方案的实施过程。一、算法:
MODIS积雪产品可以提供每天两景积雪数据,很容易想到,通过逐日比较积雪数据,可以确定“感兴趣区域”在任意相邻的两天是否发生了“降雪”或“融雪”事件。 这里可供选择的判断发生降雪或融雪的指标有:日内/日间积雪变化、日内/日间积雪反照率变化。
二、实施过程:
本程序是在之前写的一个积雪处理程序(http://user.qzone.qq.com/717191727/blog/1382349333)的基础上进一步编写而成的。
如下图
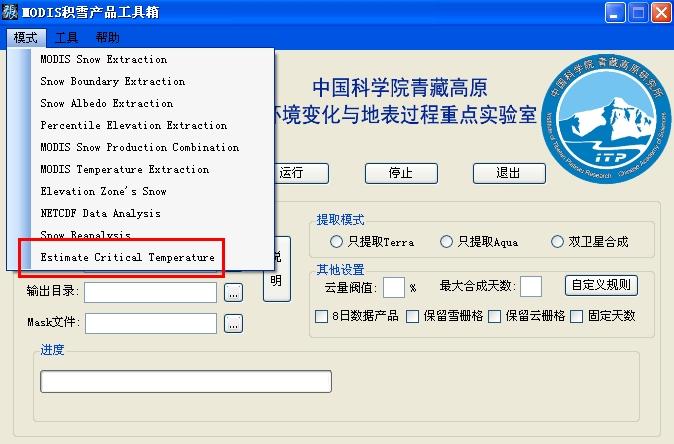
在模式下选择“Estimate Critical Temperature”就会进入估算临界气温的模式
现在,我们假设需要估算西藏自治区东部37个站点的“临界温度”,其分布如下:
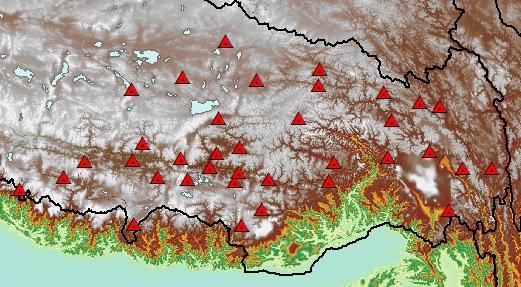
(1)首先,我们需要气象站数据。
而且,我们需要的是大量的、长时间的、逐日的气象站数据,这种数据如果都以文本格式存储,想想就头大,一个显而易见的改进想法就是采用数据库来解决这个问题,所以,我使用了开源免费的SQLite数据库系统,这样不仅节省了数据存储空间,而且“可能”会提高数据检索速度。
因此,在正式编写估算代码之前,我先写了一个子工具用于制备符合SQLite格式的气象站数据,如下
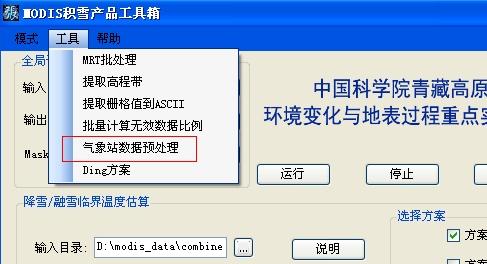
点击红框内的工具,进而
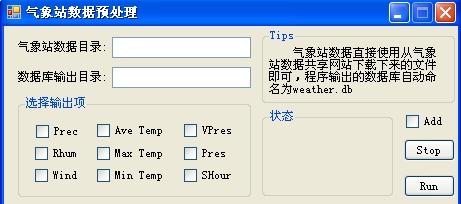
“气象站数据目录”指的是存放从“气象数据共享网站”上下载的数据文件的目录,like:

这些文件都是TXT文本文档,然后,“数据库输出目录”指的是生成的数据库文件将会输出的目录,生成的文件会自动命名为“weather.db”
”选择输出项“则是选择想要输出的字段,如图,从左向右,逐行列举,分别是:降水,日平均气温,水汽压,相对湿度,日最大气温,气压,风速,日最低气温,日照时数。
“Add”是指对已经存在的气象站数据库进行添加更新。
好了,下面实际进行操作:
先填好各个输入项
如图,设置了5个输出字段,然后,运行
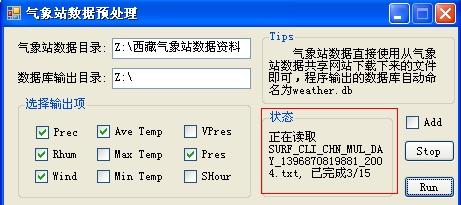
从2000年到2014年,每年一个文件,共有15个数据文件。
处理前,气象站数据文本文件共103m,生成的数据库文件为4.7m
随便使用一个SQLite数据库管理软件,打开生成的文件(weather.db)
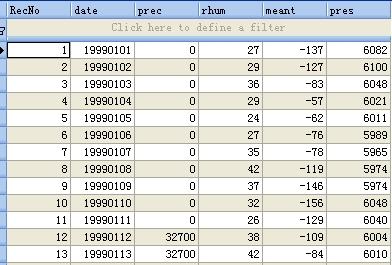
这些记录会被本程序自动识别,进而使用
(2)然后,估算两个临界温度。
进入“Estimate Critical Temperature”模式,如下图
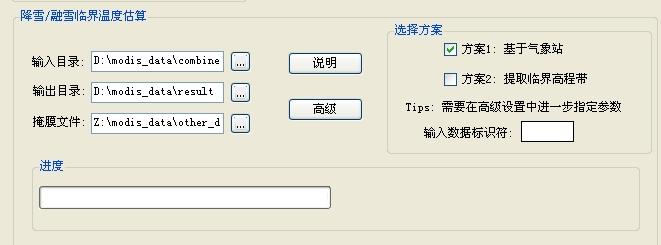
这里,输入目录指的是逐日积雪数据,输出目录则是存放结果文件的目录,同时也是程序的工作目录,掩膜文件只是为了提供一种方便,是可选的。
”选择方案“里提供了两种方案,第一种方案需要使用气象站数据,第二种方案则只需要积雪数据。
本文只涉及第一种方案
然后,点击”高级“,进入高级设置,
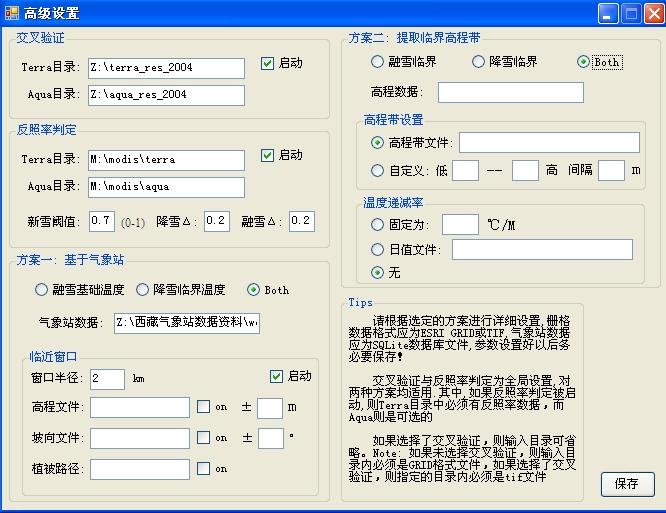
先看”交叉验证“:即,每天有两景MODIS积雪数据,分别是上午10点半过境的Terra数据和中午1点半的Aqua数据,如此,就可以通过这两个时刻的积雪状况,判断出该日是发生了降雪还是消融。
然后,”反照率判定“指的是:通常,新雪的反照率较高(>0.7),随着积雪消融,反照率逐渐降低,因此,通过反照率的变化,也能从某种角度判断是否发生了降雪或者消融。
由于每日有两个卫星平台的反照率产品,分别是Terra和Aqua卫星,所以提供了两个输入目录,但是,有文献指出Aqua产品由于传感器错误,数据没有Terra可靠,所以Aqua目录在这里是可选的。
“新雪阀值”指的是,当反照率的数值超过该值时,即判定为发生了降雪事件。
“降雪Δ”指的是,若前一时刻与当前时刻的反照率的差值>该值,则判断发生了降雪事件。反之,则是“融雪Δ”
这两个设定都是“全局设定”,即,同时适用于这两个方案。
下面看一下方案一
首先,选择要估算的参数,一目了然
![]()
这里选择“Both”,即,两个参数都要估算。
然后,指定气象站数据的路径,这里用的应当是使用前面提高的那个工具生成的文件
![]()
接着,“临近窗口”指的是:如果只考虑气象站所在的栅格,那么,在很多情况下,尤其是当云量较多的时候,我们就无法得到有效的遥感数据了,那会严重影响本方案的实用性,所以,这里采用了一个变通的思路,一般来说,气象站是可以代表周围一定范围的区域内的气象状况的,所以,这里提供了一个“窗口半径”的设置,即,以每个气象站所在的栅格为中心,开辟一个圆形窗口,如下,
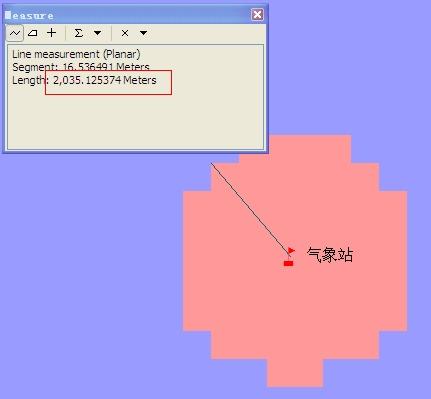
粉红色区域即为窗口覆盖区域,窗口内的栅格都会参与计算。(图示的窗口半径为2公里)
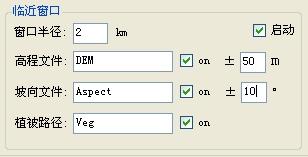
接下来,如果窗口较大的话,窗口内的“空间异质性”显然就是需要考虑的了,因此,本程序考虑了“高程”、“坡向”以及“植被”的相似性,如图所示,高程与气象站所在栅格相差不超过50米、坡向相差不到10度以及植被类型相同的栅格才会参与计算。
如此,就会在气象站周围生成一组“相似栅格”,这样就大大提高了数据的有效性。
所有参数设置好以后,点击保存。
(3)程序执行流程概述
下面,简要说一下程序在执行时所遵循的算法:
1、首先,根据用户输入的参数,判断用户使用的是“双卫星合成产品”还是单卫星产品:如果没有选定“交叉验证”,“输入目录”内就应当是“双卫星合成产品”;如果“交叉验证”被选定,则必须给出两个卫星平台的数据,而此时,“输入目录”选项就会被忽略。
2、判断是否需要掩膜
3、检查输入目录内是否有足够多的符合要求的积雪以及反照率文件,如果有的话,进行排序和日期配对。程序将只计算日期匹配的连续数据。所有不匹配的情况都会记录在log文件中,方便用户查错。
4、 检查其他数据文件的格式和空间范围,比如,DEM、植被等
5、读取气象站数据“weather.db”文件,通过表名字(table name)读入所有的”目标气象站“,本例中共有37个目标站点。
6、程序自带一个名为”stations.db”的文件,该文件内容如下:
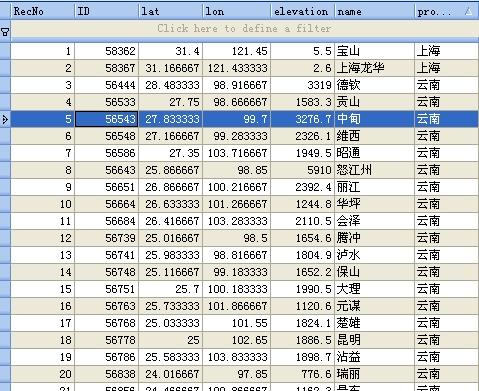
如图,该文件内记录了中国所有756个站点的编号、经纬度以及高程信息。该文件同样是SQLite数据库格式,程序会根据该文件查找出37个目标气象站的经纬度信息,然后逐步建立一个albers投影的点矢量文件,以此确定各气象站所在栅格的位置。
7、建立”索引栅格“,也就是”标记栅格“,如前所述,当启动了”临近窗口“时,就需要考虑距离、高程、植被等的相似性了,而实际上,这些相似性一般是不会随着时间发生变化的,所以,在程序开始执行时,只需要一次性建立一个标记了”相似栅格“的索引文件,就能高效、准确、方便地实现”临近窗口“的效果了。
8、前后日分析:依时间顺序,逐一分析,前后两日的积雪、反照率数据的变化,判断”降雪“或”融雪“事件,中断的日期会记录在log文件中。倘若侦测到”降雪“或”融雪“事件,则会输出在结果文件”snow.db”或”melt.db‘文件中,这两个文件同样是SQLite数据库文件。其内容类似:
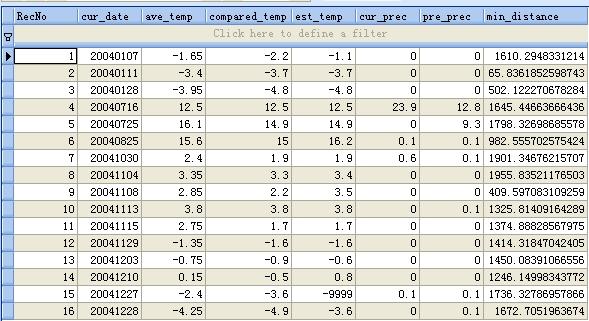
每条记录都包含了:当前日期、日平均温度、比较后的温度、估算的温度、当前日降水、前一日降水以及与对应气象站所在的栅格最近的发生事件的栅格的距离(可用于区分同时发生降雪、融雪的情况)
(4)其他:丁方案
之前,所里的学霸师姐ding baohong已经做过了类似的参数估算工作(其实,如果我知道学霸师姐已经做了,我真心不会再做这个选题,学渣实在是悲催),但是使用的方法以及数据完全不一样,而且用途也不一致(师姐的方案里没有估算融雪基础温度),为了对比验证,我的导师让我再用该师姐的方案算一下,所以,我将师姐的Matlab代码重写为“等效”的c++代码,并编译成动态链接库,使用这个程序进行调用,做成一个小工具,如下图:
点开“Ding”方案:
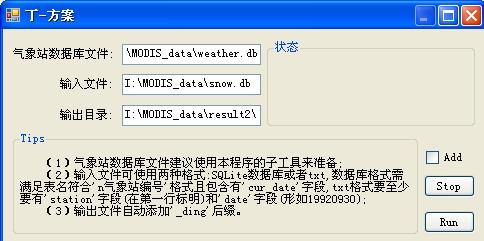
将前一步生成的结果文件(snow.db)作为输入文件,设置好其他路径,即可在结果中逐条添加”Ding方案”的估算结果。
三、后记
目前只实现了“方案一”,实际上,我个人觉得,“方案二”对“度日模型”的作用更大,有了“方案一”做基础,方案二的实现也就非常容易了。
之后的工作就是对“温度递减率”的估算了,想想就头痛~